
ScaleArc supports a number of replication topologies. These include the following for MySQL, version 5.7.x:
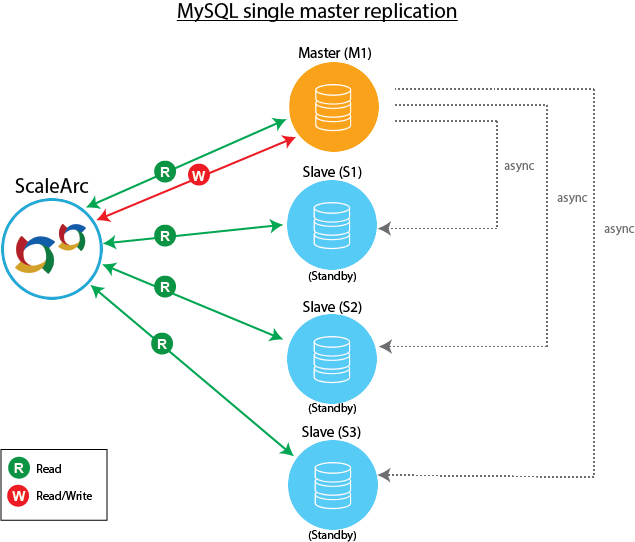
Master with slaves (single replication)
This is the most straightforward MySQL replication topology. A master (M1) receives writes; one or more slaves (for example, S1, S2, and S3) are in standby mode and replicate from the same master via asynchronous replication. If the designated master goes down, ScaleArc promotes the most up-to-date slave (for example, S1) as the new master for receiving writes. The remaining slaves resume the replication from the new master.
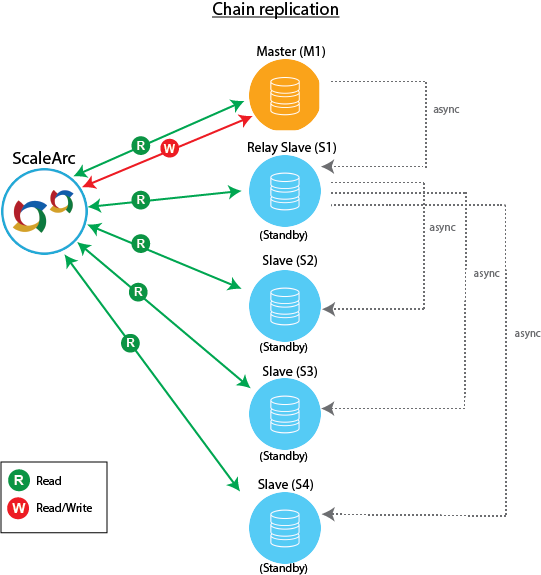
Master with relay slaves (chain replication)
This topology addresses the network interface overload that results when a master has many slaves connected to it. The setup uses a master (M1) configured as a Read/Write server and an intermediate "master" or slave server (S1) in standby mode to act as a relay to one or more slaves (for example, S2 and S3) in the replication chain. Read replicas pull the replication stream from the Relay server to offload the master server. The setup requires that you enable the binary logging and log_slave_updates on the slave Relay server.
When ScaleArc detects the master is down, it triggers a failover and designates the Relay server as the master to receive Read/Write traffic; the read servers now log reads form the new master.
Master with active master (circular replication)
Also known as ring topology, this setup requires two or more MySQL servers that act as master. The masters receive writes when configured as Read/Write in ScaleArc and generate binary logs.
In this setup, ScaleArc connects to two masters (M1 and S1 which is in the role of a second master); you can configure both masters for Read/Write traffic or keep one in standby mode. Failover occurs differently in each configuration. In a configuration where M1 is a Read/Write server and S1 is in standby mode, ScaleArc initiates a failover when the Read/Write server goes down. If you have two or more masters configured as Read/Write servers, ScaleArc does not initiate a failover when one of the servers are down.

Master with backup master (multiple replication)
The setup uses asynchronous replication between master and the backup master. The master (M1) pushes changes to a backup master (M2) and to one or more slaves (for example, S1 and S2). ScaleArc stores all the data in the backup server (S2). When the master (M1) with Read/Write traffic goes down, ScaleArc routes the write traffic to M2. The backup server now stores the data from M2.

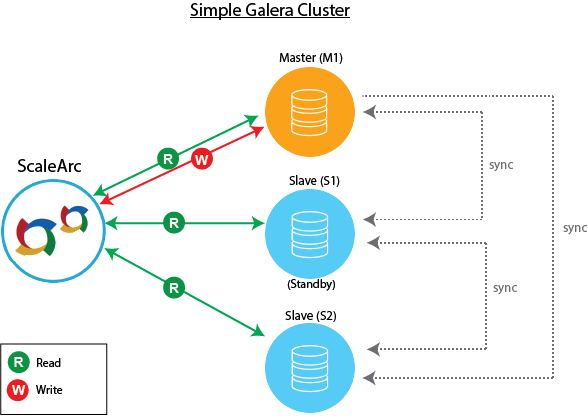
A simple Galera cluster
This topology configures the databases in synchronous replication mode. Following Auto failover, a switchover occurs and S1 or S2 becomes the active master. The databases do not register any change in the backend as they are already in synchronous replication mode.
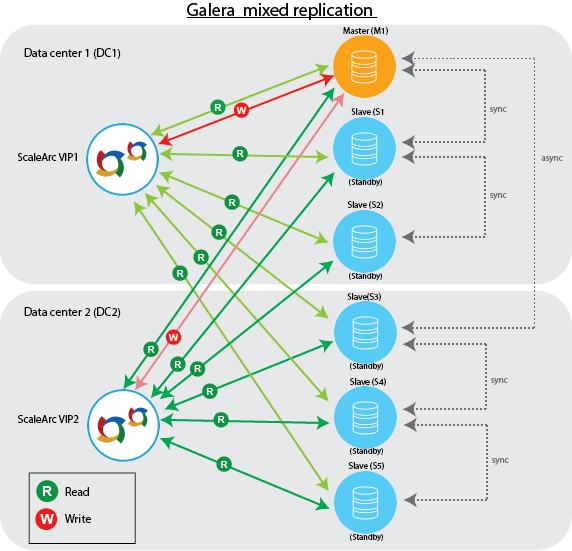
Galera--mixed replication topology
This topology achieves disaster recovery(DR)/Geographic redundancy (GR). It is best illustrated with two data centers (DC1 and DC2, respectively). Note that DC1 may be in a different geographic location than DC2.
Each data center has one highly-available ScaleArc pair and two or more databases in a Galera group. Each ScaleArc cluster is configured with all the available databases. However, only the first database is in Read/Write mode; the second data center is similarly configured. Both ScaleArc clusters are similar; only the two VIP addresses are different. In such a configuration, each ScaleArc cluster is available to applications independently.
The databases within a Galera group (for example, M1, S1 and S2 in DC1 and S3, S4, and S5 in DC2) are synchronous with each other, within their respective data centers. Additionally, the first database of each Galera group (that is, M1 and S3, respectively) are in GTID-based asynchronous Master-Master (M-M) replication with each other.
ScaleArc uses an External API script to handle failover and switchover. For example, when the master M1 in DC1 goes down, ScaleArc initiates a failover to standby slave S1, which takes on the role of the master. S3 in DC 2 now points to the new master in DC1 in M-M replication mode.
In the event that DC1 goes down completely, the External API script in DC2 appoints one of the healthy standby slaves as the new master.
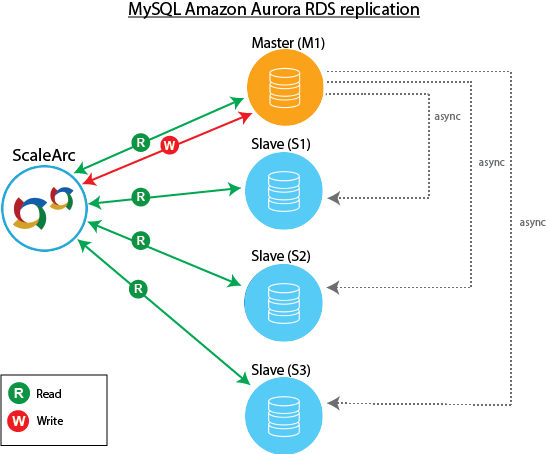
Amazon Aurora RDS (monitoring)
ScaleArc supports Amazon Aurora and leverages the latter's failover management system. ScaleArc reflects the state change on its dashboard.
Comments