
ScaleArc's load balancing decisions depend on how you configure settings such as Read/Write split and Query Level Load Balancing.
Query routing allows ScaleArc to override the load balancing decisions by using policies that route a specific query to a specific database server or a set/type of database servers. A simple use case is where you can run the reporting workload from a specific database node by specifying a user-based rule on ScaleArc.
Additionally, the query routing feature enables sharding at the database level without requiring you to make changes to the application. You can create query routing rules on ScaleArc to specify the shard to which the incoming query should be forwarded.
Set up load balancing policy
- Click Clusters > Settings > Load Balancing and Routing.
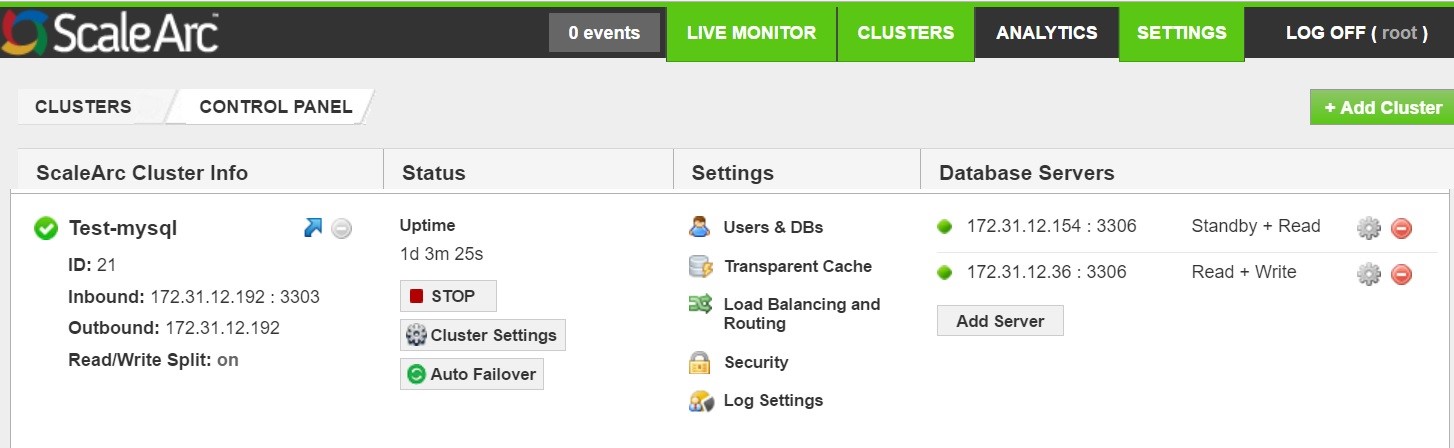
- Click Load Balancing Policies.
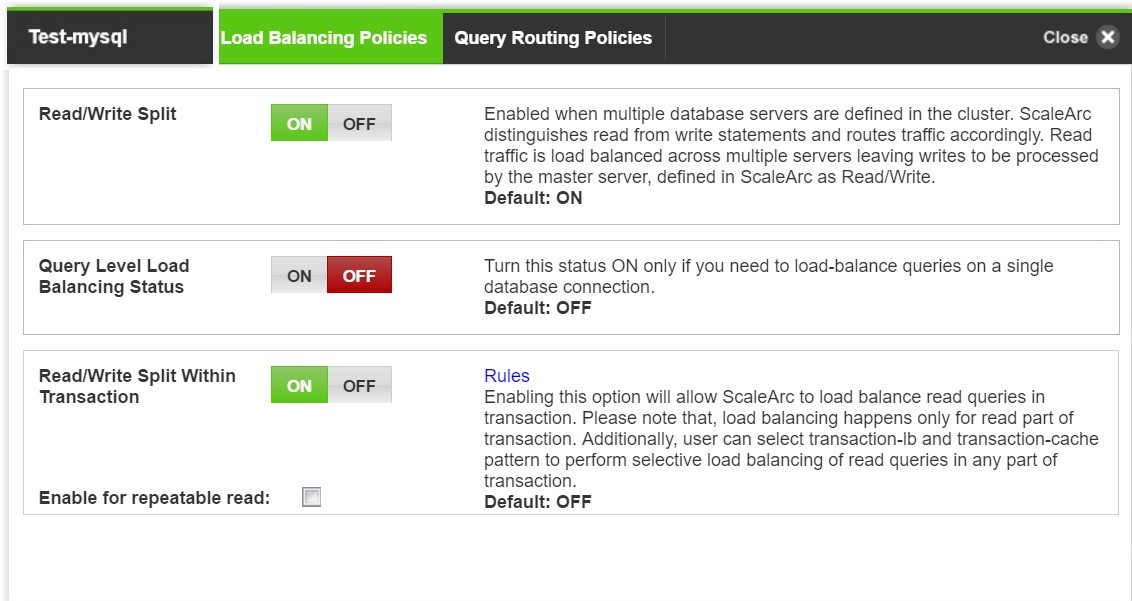
3. Configure as follows:
| Field/Button | Description | |
|---|---|---|
| Read/Write Split |
Enabled when multiple database servers are defined in the cluster. ScaleArc distinguishes Read from Write statements and routes traffic accordingly. Read traffic is load balanced across multiple servers, while Write traffic is processed by the principal server, defined in ScaleArc as Read/Write. For typical principal replica environments, Read/Write split should be turned ON so that ScaleArc can send Reads to replicas and everything else (+ some Read traffic) to the principal server. |
Default is ON. |
| Query Level Load Balancing Status |
Load balances queries on a single database connection. This is an optional setting. |
Default is OFF. See below for configuration options when this setting is ON. |
| Read/Write Split Within Transaction |
Enabling this option will allow ScaleArc to load balance read queries within a transaction. Please note that, load balancing happens only for the read part of a transaction. Additionally, users can provide transaction load balancing and transaction cache pattern to perform selective load balancing and caching of read queries in any part of transaction. Enable for repeatable read - select this option to enable read/write split within transaction for server with repeatable read level of isolation. |
Default is OFF. |
Query Level Load Balancing
Query Level Load Balancing balances queries on a single database connection. When this option is enabled the following options can be configured.

Configure as follows:
Field/Button Description User input/Default Sticky Connection on Write Queries Turn the status OFF only if you need to load balance queries received after a write query on a particular connection.
Default is ON. Query Level Sticky Query Enter the number of read queries after a write query to send to the same DB server after a write query is executed. Connection will un-stick from the DB server after those many read queries are executed.
Default is 1.
Configuring Rules
Click on Rules to configure various patterns/rules for load balancing within transaction.
Transaction Pattern
Follow the steps below to configure a transaction pattern which will decide the behavior for caching, load balancing, and read ignore for transactions. You can also enable/disable a pattern.
- Click on the gear icon to add/configure patterns for the databases.

- Enter the patterns.

Complete the entries as follows:
Field/Button Description User input ADD Pattern button Opens the related screen. Create a pattern and ensure that it's entered in the order in which you want it executed. Order Specifies the order in which the query should be executed. Enter the order. Rules Enter the pattern's regular expression. Enter the rule. Time To Live Defines when the cache expires. Enter a value when you create a pattern. Read Ignore This option allows ScaleArc to treat matching queries as write instead of read. This applies only in transaction. Select enabled/ disabled Cache This option allows ScaleArc to perform caching of matching queries in tranasaction. Select enabled/ disabled LB This option allows ScaleArc to perform load-balancing of matching queries in tranasaction. Select enabled/ disabled Enabled Disables or enables a transaction rule from executing, depending on its state. You can enable or disable this option during or after you create the pattern. The default is enabled. Delete icon You can also click on the delete icon to delete the cache rule. Click icon to delete
Write Ignore Rules
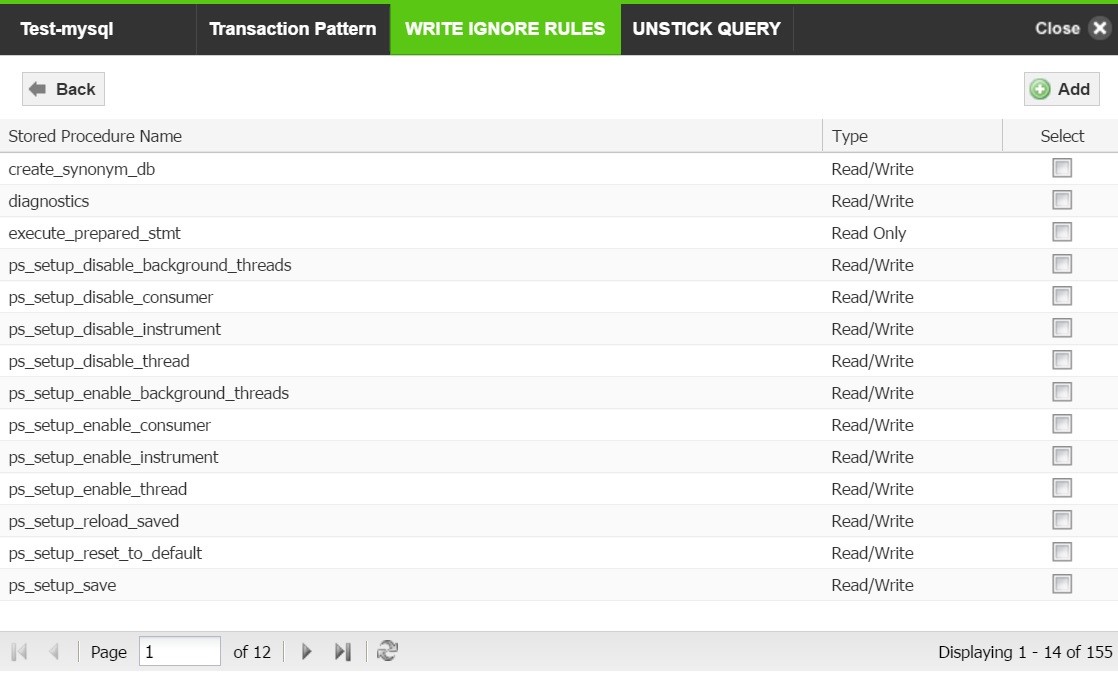
Follow the steps below to configure stored procedure which will exclude certain MySQL queries from being detected as write queries.
- Click on the Write Ignore Rules tab.
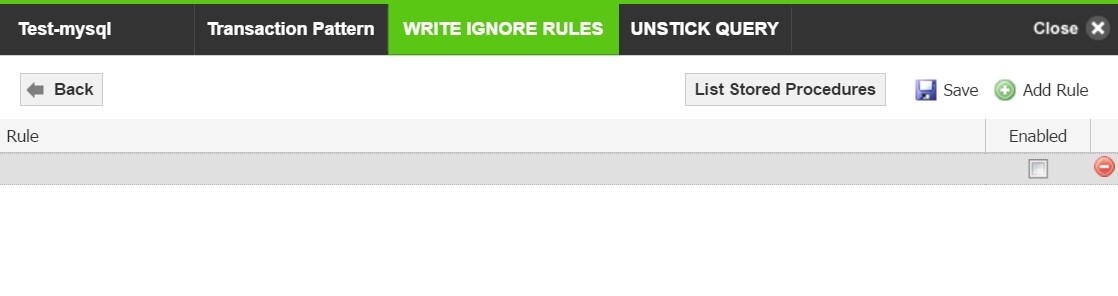
- Click on Add Rule to add write ignore rules for the database. Click on Save.
- Click on List Stored Procedures to view the list of write ignore rules created.
Unstick Query
Query patterns created here will be matched against each query. If matched, connections will unstick from the existing server connection.
- Click on the Unstick Query tab.
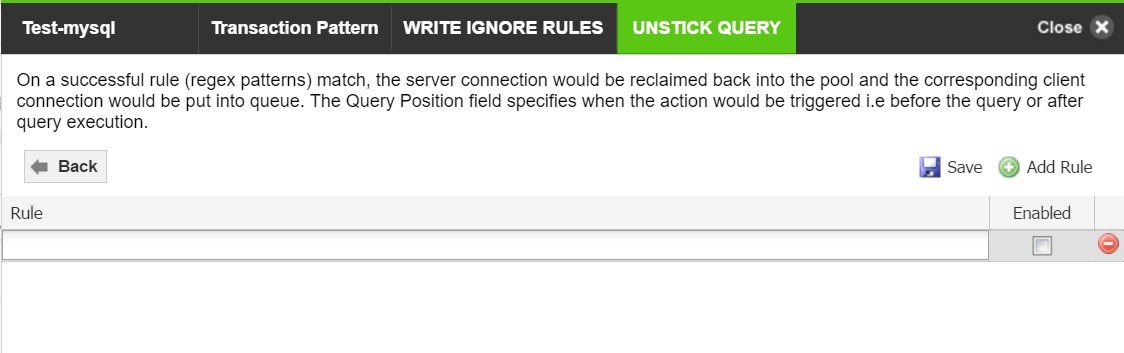
- Click on Add Rule to create a query pattern for an unstick query. Click on Save.
Set up query routing policy
You can leverage the query routing feature to route to a database server or to a shard database; alternatively, you can choose to do both. Note that in the event of a conflict, Read/Write split decision takes precedence over a query routing decision. For example, if a stored procedure matches a routing rule which has only Read database node(s) but if that stored procedure is not part of the Write Ignore rule it does not get sent to the Read database node; instead the system generates a custom error message for the client. If all the database nodes matching the query routing rule are marked unhealthy then the normal queuing logic kicks in.
- On the ScaleArc dashboard, click Clusters > Settings > Load Balancing and Routing.
- Click on the Query Routing Policies tab.
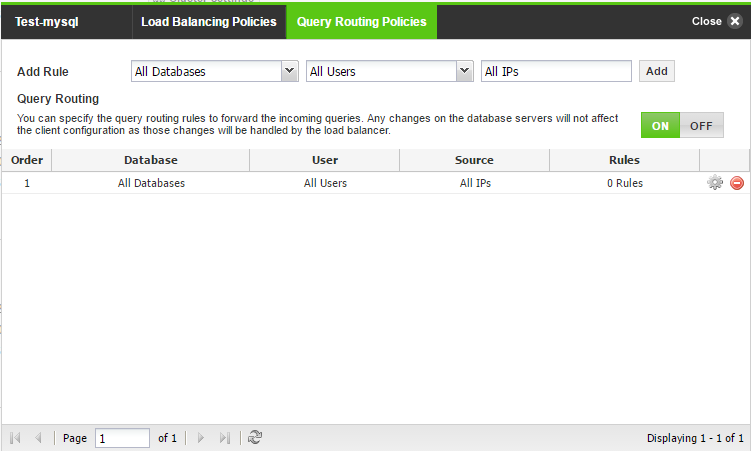
- Turn ON the Query Routing option.
- Add a query-routing rule by selecting the database(s), user(s), and one or more IP addresses. This creates a group to which you can add more granular rules as per you requirement by providing the exact query pattern.
- Click the Gear icon against the database of choice to edit the rules.
Create specific query-routing rules
You can create specific rules manually to direct queries to databases or shards if they are very complex and specific to your requirements. Alternatively, you can use the ScaleArc GUI to generate a query-routing rule for a specific sharding requirement.
Set the rule manually
Follow these steps to manually create a rule for query-routing to databases or to a shard:
- Click the Gear icon against the database of choice to edit the rules.
- Turn ON Rule Status.
- Click Add.
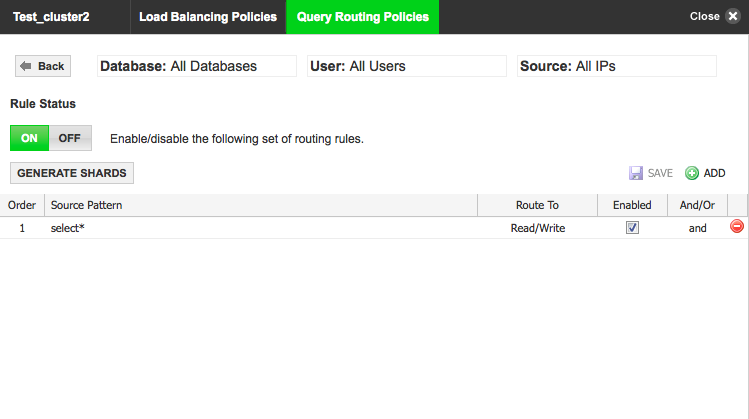
Complete the entries as follows:
Field/Button Description User input Order Specifies the order in which the query should be executed. Enter the order. Source Pattern The query routing pattern. Enter the query routing pattern. Route To The target destination for the pattern. You have a choice to send the queries to Read Only or to a Read/Write server. Once the query gets matched with the rule it gets diverted to the database server, based on the type of server added in the cluster.
Route the query to an IP address or a type of server. Check box Indicates whether the rule is enabled or disabled. Select the checkbox to enable. AND/OR rule The AND rule uses the default load-balancing logic that has been defined in the cluster. The database servers do not have any priority, with respect to the route. The queries are load-balanced among all the selected database nodes.
The OR rule is a prioritized list of servers. The specified order indicates the priority in which a database server is chosen to route the query. The queries are always sent to first database node in the list if it's healthy; otherwise it's sent to next database node in the list.
Choose a rule type. Click Save.
Creating Shard Rules
Follow these steps to create shard rules.
- Click the Gear icon in the Add Rule screen to open the screen.
- Select Generate Shards and configure appropriately.
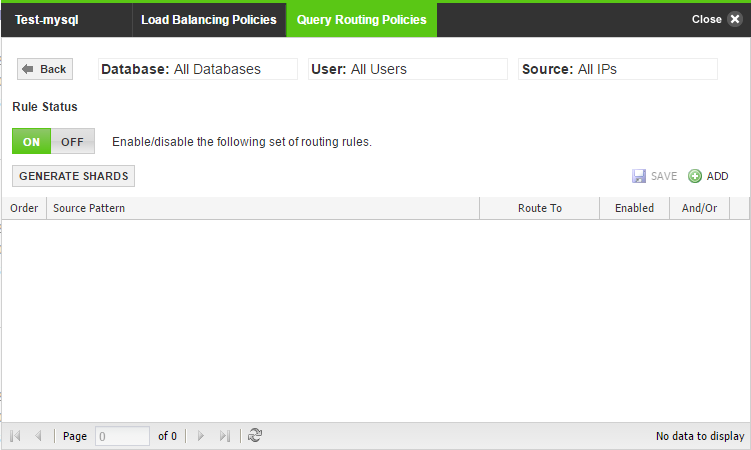
- Click Generate Shards to open the screen.
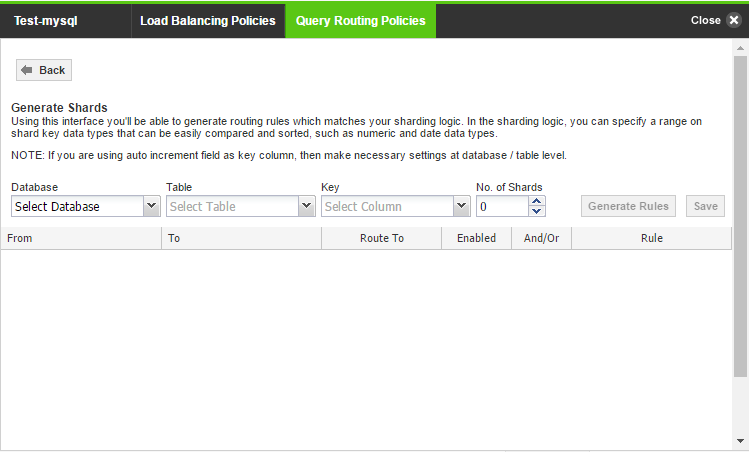
Then, complete the entries as follows:
Item Description User input Database column Select the database. Select a database from the drop down. Order Specifies the order in which the query should be executed. Enter the order. Table column The database table to which the query is routed. Select from a drop down menu. Key column The table column key for the query routing rule. Select from a drop down menu. Number of shards The number of shards you would like to create. Enter a number. From and To range Entries allow the key column to generate routing patterns. Specify the range. Route To The target destination for the pattern. You have a choice to send the queries to Read Only or to a Read/Write server. Once the query gets matched with the rule it gets diverted to the database server, based on the type of server added in the cluster.
Route the query to an IP address or a type of server.
Checkbox Indicates whether the rule is enabled or disabled. Select the checkbox to enable. AND/OR rule The AND rule uses the default load-balancing logic that has been defined in the cluster. The database servers do not have any priority, with respect to the route. The queries are load-balanced among all the selected database nodes.
The OR rule is a prioritized list of servers. The specified order indicates the priority in which a database server is chosen to route the query. The queries are always sent to first database node in the list if it's healthy; otherwise it's sent to next database node in the list.
Choose a rule type. - Click Generate Rules and save.
Comments